2023. 3. 28. 23:57ㆍNatural Language Processing
먼저 단어 임베딩(word embedding)이란 무엇인가?
What is word embedding?
Word embedding or word vector is an approach with which we represent documents and words. It is defined as a numeric vector input that allows words with similar meanings to have the same representation. It can approximate meaning and represent a word in a lower dimensional space. These can be trained much faster than the hand-built models that use graph embeddings like WordNet.
출처 : https://www.turing.com/kb/guide-on-word-embeddings-in-nlp
Word embeddings in NLP: A Complete Guide
Word Embeddings is an advancement in NLP that has skyrocketed the ability of computers to understand text-based content. Let's read this article to know more.
www.turing.com
위 사이트의 설명에 따르면, 단어 임베딩이란 단어를 특정 길이의 숫자 벡터로 나타냄으로써 벡터가 그 단어의 의미를
근사시킬 수 있도록 하는 기법이다.
이번 장에서는 사전 훈련된 단어 임베딩을 이용하여 기사 제목(title)에 따른 카테고리를 분류하는 신경망을 학습시킨다.
먼저 우리가 구현하고자하는 객체는 크게 Vocabulary, Vectorizer, Classifier 3가지가 있다.
구현을 통해서 이 각각이 하는 역할에 대해서 알아보고 분류 작업을 수행하는 신경망을 수행하도록 하자.
class Vocabulary(object):
def __init__(self, token_to_idx = None):
if token_to_idx is None:
token_to_idx = {}
# 없으면 새로 생성
self._token_to_idx = token_to_idx
self._idx_to_token = {idx:token for token, idx in self._token_to_idx.items()}
#역 딕셔너리도 생성Vocabulary에서는 token을 index로, 반대로 index를 token으로 바꾸는 딕셔너리를 가진다.
이 딕셔너리가 어휘사전의 역할을 한다.
def to_serializable(self):
return {'token_to_idx': self._token_to_idx}위 함수는 해당 형식으로 token_to_idx 딕셔너리를 반환한다.
def add_token(self, token):
#token을 인자로 받아서
if token in self._token_to_idx:
index = self._token_to_idx[token]
#token_to_idx에 이미 존재하면 토큰에 해당하는 index를 반환한다
else:
#새로 발견한 토큰이면
index = len(self._token_to_idx)
#딕셔너리의 가장 마지막 인덱스에
self._token_to_idx[token] = index
#토큰을 추가한다.
self._idx_to_token[index] = token
return index
새로 발견한 토큰을 token_to_idx에 추가해주는 함수이다.
def add_many(self, tokens):
#tokens에 있는 모든 토큰들을 다 추가해준다.
return [self.add_token(token) for token in tokens]그리고 토큰 여러개를 token_to_idx에 추가해주는 함수이다.
def lookup_token(self, token):
#token에 해당하는 index를 찾는다.
return self._token_to_idx[token]
def lookup_index(self, index):
#index에 해당하는 token을 찾는다.
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary."%index)
return self._idx_to_token[index]두 딕셔너리를 기반으로 토큰을 idx로, idx를 토큰으로 찾아주는 함수이다.
class SequenceVocabulary(Vocabulary):
def __init__(self, token_to_idx = None, unk_token="<UNK>",
mask_token="<MASK>", begin_seq_token="<BEGIN>",
end_seq_token="<END>"):
super(SequenceVocabulary, self).__init__(token_to_idx)
self._unk_token = unk_token
self._mask_token = mask_token
self._begin_seq_token = begin_seq_token
self._end_seq_token = end_seq_token
#인자로 받은 토큰들을 self 변수에 담는다.
self.unk_index = self.add_token(self._unk_token)
self.mask_index = self.add_token(self._mask_token)
self.begin_seq_index = self.add_token(self._begin_seq_token)
self.end_seq_index = self.add_token(self._end_seq_token)
#각 토큰들을 딕셔너리에 추가해주고, 토큰에 해당하는 인덱스도 self 변수로 저장해둔다.그리고 이 vocabulary를 상속하는 SequenceVocabulary이다. 문장을 구분하기 위해 각 특별 토큰들을 인자로 받아서
이 특별 토큰들을 token_to_idx, idx_to_token에 추가해준다.
def lookup_token(self, token):
if self.unk_index >= 0:
#unk_token이 있으면
#token이 없을 경우에 unk_token을 반환한다.
return self._token_to_idx.get(token, self._unk_token)
else:
return self._token_to_idx[token]딕셔너리의 get 함수는 첫번째 인자가 없을 경우에 두번째 인자를 반환한다.
정리하자면 Vocabulary의 역할은 토큰을 임베딩하기 위한 전 단계로서, 토큰을 식별하고 이에 대한 인덱스를 부여한다.
이 딕셔너리를 '어휘 사전'이라고 한다. 그리고 색인을 쉽게하기 위해 인덱스를 통해 토큰을 찾을 수 있도록 조치한다.
다음으로 Vectorizer에 대해 알아보자.
class NewsVectorizer(object):
def __init__(self, title_vocab, category_vocab):
#title, category 어휘사전을 각각 저장한다.
self.title_vocab = title_vocab
self.category_vocab = category_vocab먼저 초기화 단계에서 기사 제목(title) 그리고 카테고리에 대한 어휘사전을 저장해준다.
def vectorize(self, title, vector_length =-1):
indices = [self.title_vocab.begin_seq_index]
#begin index로 스타트를 끊어주고
indices.extend(self.title_vocab.lookup_token(token) for token in title.split(" "))
#title을 구성하는 각 토큰에 해당하는 index를 하나하나 추가해준다.
if vector_length<0:
#최대 벡터길이가 지정되어있지 않으면
vector_length = len(indices)
#토큰들의 갯수만큼의 벡터길이로 생성한다.
out_vector = np.zeros(vector_length, dtype=np.int64)
out_vector[:len(indices)] = indices
out_vector[len(indices):] = self.title_vocab.mask_index
#벡터길이가 title의 토큰 수 길이보다 길다면 나머지를 mask_index로 채워준다.
return out_vectorvectorize 함수에서는 기사 제목(title)을 인자로 받는다. 제목은 문장이며, 문장은 단어(토큰)으로 이루어져 있다.
토큰들은 Vocabulary를 통해 어휘사전에 담겨있는데, 이 어휘사전에서 토큰에 해당하는 인덱스를 찾아서
각 인덱스의 시퀀스로 title을 표현해준다. 거기에 우리가 설정한 특별한 토큰들을 추가해준다.
@classmethod
def from_dataframe(cls, news_df, cutoff = 25):
category_vocab = Vocabulary()
#기사 분류(Category)에 대한 어휘사전을 제작한다.
for category in sorted(set(news_df.category)):
category_vocab.add_token(category)
word_counts = Counter()
#특정 cutoff 이상의 출현빈도를 가진 단어들만 단어사전에 넣기 위해 Count한다.
for title in news_df.title:
for token in title:
if token not in string.punctuation:
word_counts[token] += 1
title_vocab = SequenceVocabulary()
for word, word_counts in word_counts.items():
if(word_counts >= cutoff):
#cutoff 이상의 출현빈도를 가진 token들만
title_vocab.add_token(word)
#title 어휘사전에 추가한다.
return cls(title_vocab, category_vocab)Vectorizer의 진입 메소드이다. 데이터프레임을 인자로 받으면, title과 category에 대한 어휘사전을 각각 생성 후에
이 데이터프레임에서 토큰들을 식별해서 각 어휘사전을 업데이트해준다.
그리고 이 어휘사전들을 바탕으로 vectorize 함수에서 title을 벡터화해주는 것이다.
정리하자면 vectorizer는 vocabulary에서 생성한 어휘사전을 바탕으로 토큰의 시퀀스(문장)을 하나의 숫자 벡터로
변환해주는 역할을 한다.
class NewsDataset(Dataset):
@classmethod
def load_dataset_and_make_vectorizer(cls, news_csv):
news_df = pd.read_csv(news_csv)
train_news_df = news_df[news_df.split == 'train']
return cls(news_df, NewsVectorizer.from_dataframe(train_news_df))Dataset 객체에서 이 일련의 과정을 통해 dataframe의 각 데이터들을 하나하나 벡터화해준다.
class NewsClassifier(nn.Module):
def __init__(self, embedding_size, num_embeddings, num_channels,
hidden_dim, num_classes, dropout_p,
pretrained_embeddings=None, padding_idx=0):
super(NewsClassifier, self).__init__()
if pretrained_embeddings is None:
self.emb = nn.Embedding(embedding_dim=embedding_size,
num_embeddings=num_embeddings,
padding_idx=padding_idx)
else:
pretrained_embeddings = torch.from_numpy(pretrained_embeddings).float()
self.emb = nn.Embedding(embedding_dim=embedding_size,
num_embeddings=num_embeddings,
padding_idx=padding_idx,
_weight=pretrained_embeddings)마지막으로 Classifier에서는 (벡터화된) title을 임베딩, 컨벌루션, 선형회귀에 차례로 통과시켜서 특정 카테고리를
예측하는 신경망을 생성한다.
pretrained_embedding이 있다면 이 사전훈련된 단어 임베딩을 활용하고, 이것이 없다면
단어 임베딩을 랜덤한 값으로 생성하고 이후에 이를 훈련시킨다.
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=embedding_size,
out_channels=num_channels, kernel_size=(3,)),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=(3,), stride=(2,)),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=(3,), stride=(2,)),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=(3,)),
nn.ELU()
)
self._dropout_p = dropout_p
self.fc1 = nn.Linear(num_channels, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)임베딩 계층을 통과한 후에는 컨벌루션과 2개의 선형 회귀식을 통과하여 최종 카테고리를 생성할 수 있도록한다.
def forward(self, x_in, apply_softmax=False):
# 임베딩을 적용하고 특성과 채널 차원을 바꿉니다
x_embedded = self.emb(x_in).permute(0, 2, 1)
features = self.convnet(x_embedded)
# 평균 값을 계산하여 부가적인 차원을 제거합니다
remaining_size = features.size(dim=2)
features = F.avg_pool1d(features, remaining_size).squeeze(dim=2)
features = F.dropout(features, p=self._dropout_p)
# MLP 분류기
intermediate_vector = F.relu(F.dropout(self.fc1(features), p=self._dropout_p))
prediction_vector = self.fc2(intermediate_vector)
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector신경망의 순전파 과정이다.
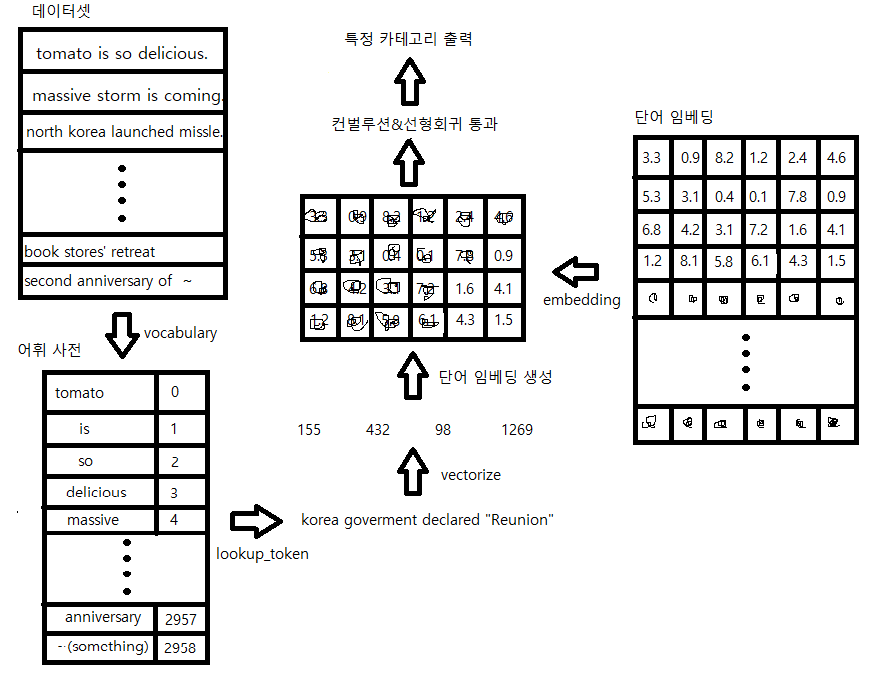
지금까지 구현한 일련의 처리과정을 하나의 그림으로 도식화하였다.
먼저 데이터셋을 읽어가면서 토큰 하나하나 어휘 사전에 추가해준다.
그리고 이 생성된 어휘사전을 바탕으로 특정 토큰의 시퀀스를 일련의 인덱스로 바꿔준다.(vectorize)
그리고 단어 임베딩에서 이 벡터의 원소에 해당하는 단어 벡터들을 추출한다.
(여기서 사용하는 단어 임베딩은 미리 다른 사람이 훈련시킨 단어 임베딩을 사용할 수 있다.
사전 훈련된 단어 임베딩이 존재하지 않는다면 random한 값으로 단어 임베딩을 생성해주어야한다.)
이 단어벡터들을 합성곱 신경망과 선형회귀에 순차적으로 통과시켜줌으로써 특정 카테고리를 출력한다.
'Natural Language Processing' 카테고리의 다른 글
| [NLP] Attention (0) | 2023.02.26 |
|---|---|
| [NLP] Seq2seq (0) | 2023.02.26 |
| [NLP] LSTM(Long Short-Term Memory) (0) | 2023.02.25 |
| [NLP] RNN(순환 신경망) (0) | 2023.02.22 |
| [NLP] word2vec 개선 - 임베딩, 네거티브 샘플링 (0) | 2023.02.19 |