2023. 2. 26. 21:58ㆍNatural Language Processing
이전 장에서는 하나의 시계열을 입력받아 다른 시계열을 출력하는 Seq2seq 모델에 대해서 살펴보았다.
이번 장에서는 NLP에서 가장 중요한 개념 중 하나인 Attention이 무엇인지 알아보고 구현해보도록 하겠다.
간단한 seq2seq 모델에서는 Encoder로부터 마지막 시점의 은닉 상태(h)만을 이어 받아
Decoder가 이 은닉상태(h)에만 의존한 채 학습을 해나갔다.
마지막 은닉상태 말고 전체 은닉상태를 활용하는 방법이 있다면 더 좋은 학습이 이루어질 수 있다.
Encoder에서 생성하는 각 시점의 은닉상태들(hs)의 정보를 Decoder에게 전달하는 방법이 Attention이다.
Attention은 말그대로 '주목' 이므로 Decoder가 Encoder의 어떤 시점의 은닉상태에 주목해야할지를 정해준다.
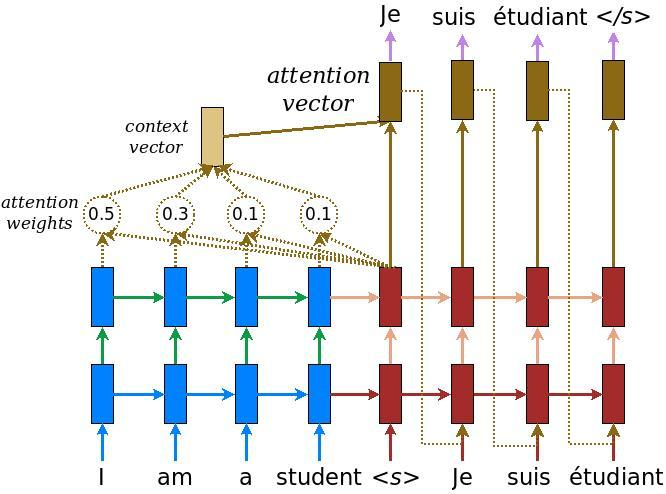
Attention에서는 Encoder의 각 시점마다의 은닉상태에 가중치를 부여하고, 이 가중치된 은닉상태를 하나로 합쳐서
하나의 맥락 벡터(Context Vector)를 만들어낸다. 다시 말해 Encoder가 출력하는 전체 은닉상태의 '총합'인데,
단순한 총합이 아니라, 은닉 벡터마다 가중치가 존재해서 이 중요도(가중치)가 반영된 은닉 상태의 전체 정보를
맥락 벡터가 담고있는 것이다.
Attention이 적용된 Seq2seq에서는 이 문맥 벡터(c)를 은닉 벡터(h)와 결합한 정보를 Affine 계층에 통과시킨다.
단순히 은닉상태만을 Affine 계층에 주었을 때보다 더 많은 정보를 전달할 수 있다.
이제 Attention을 구현해보도록 하자.
class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = NoneAttention 계층은 Encoder의 은닉벡터 모음과 Decoder의 t 시점의 은닉벡터를 통해 시점 t의 맥락 벡터를 만들어내는
계층이다.
def forward(self, hs, h):
#Encoder로부터 받은 전체 은닉상태 hs 이어받는다.
a = self.attention_weight_layer.forward(hs, h)
#Decoder의 은닉상태 h와 Encoder의 전체 은닉상태 hs와의 유사도 계산(가중치)
out = self.weight_sum_layer.forward(hs, a)
#은닉상태와 가중치를 곱하여 현재 시점(t)에서의 문맥 벡터 c를 출력
self.attention_weight = a
return out순전파(forward)는 맥락 벡터를 생성해낸다.
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh역전파 과정은 위와 같다. Encoder로 전달할 역전파 dhs와 Decoder로 전달할 역전파 dh를 만들어낸다.
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None전체 시점 T에 대한 Attention 과정을 한번에 수행하는 계층이다.
def forward(self, hs_enc, hs_dec):
N, T, H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:, t, :])
#하나의 Attention 계층을 생성해서 Encoder의 전체 hs와 Decoder의 t시점의 h를 통해
#t시점의 맥락 벡터 c를 생성한다.
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return outEncoder의 은닉 상태 모음(hs_enc)과 Decoder의 LSTM 계층이 생성한 은닉상태 모음(hs_dec)을 입력받아
전체 시점의 맥락 벡터(c)를 생성해낸다.
각 시점마다의 Attention 가중치들을 배열에 저장해준다.
위 배열을 통해서 각 시점마다 Decoder가 Encoder의 어느 시점에 주목한 것인지 알 수 있다.
def backward(self, dout):
N, T, H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
#각 시점마다의 dhs를 누적해서 Encoder에 전달한다.
dhs_dec[:, t, :] = dh
return dhs_enc, dhs_decTimeAttention의 역전파는 위와 같다.
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
.
.
affine_W = (rn(2*H, V) / np.sqrt(2*H)).astype('f')
#Decoder의 출력 h와 문맥벡터 c가 이어붙여지므로 2*H
.
.
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
#Decoder의 출력 h와 문맥 벡터 c를 이어붙인다.
score = self.affine.forward(out)
return scoreAttention 기법을 처리하기 위한 Decoder이다.
Affine 계층에서 2*H 형상의 데이터를 V 형상의 데이터로 바꿔주는데, 은닉 벡터 길이인 H의 2배를 입력받는 이유는
Attention 계층에 의해 맥락 벡터 c와 은닉벡터 h가 이어붙여졌기 때문이다.
Decoder의 forward는 데이터를 임베딩하고, LSTM 계층에 통과시켜 은닉 벡터들(hs)을 생성한 후에
Attention 계층으로 맥락 벡터를 생성하여 은닉 벡터와 결합한다.
이 결합한 벡터를 Affine 계층에 통과시켜 어휘 사전 크기(vocab_size)만큼의 score를 생성한다.
이 score를 단어마다의 '확률'로 생각할 수 있고, 이를 통해 다음 출현할 단어를 예측할 수 있다.
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampledAttention Decoder의 Sequence 생성 과정이다.
'Natural Language Processing' 카테고리의 다른 글
| [NLP] 단어 임베딩을 이용한 기사 분류 신경망 (1) | 2023.03.28 |
|---|---|
| [NLP] Seq2seq (0) | 2023.02.26 |
| [NLP] LSTM(Long Short-Term Memory) (0) | 2023.02.25 |
| [NLP] RNN(순환 신경망) (0) | 2023.02.22 |
| [NLP] word2vec 개선 - 임베딩, 네거티브 샘플링 (0) | 2023.02.19 |