9-4. 군집(Clustering) - DBSCAN
2021. 5. 23. 03:41ㆍMachine Learning
Kmean 클러스터와 더불어 군집의 대표적인 알고리즘이 DBSCAN이다.
DBSCAN의 클러스터링 과정은 다음과 같다.
1. 각 샘플별 기준 거리 ε(입실론) 내 샘플의 갯수를 측정한다. 이 지역을 샘플의 ε-이웃이라고 한다.
2. ε-이웃 내에 적어도 지정된 m개 샘플이 있다면 이를 핵심 샘플로 간주한다.
3. (조건 2를 만족하며) 핵심 샘플의 이웃에 있는 모든 샘플은 동일한 클러스터에 속한다.
4. 핵심샘플도 아니며 이웃도 아니라면 이상치로 판단한다.
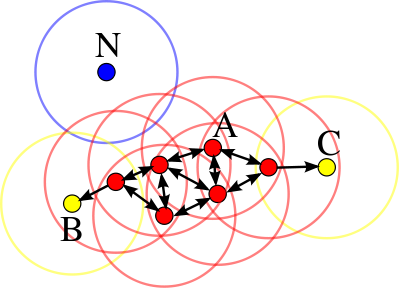
출처 : https://en.wikipedia.org/wiki/DBSCAN
위 그림은 DBSCAN에 의해 분류된 케이스를 나타낸다. 지정된 최소샘플수(minPts)는 4로 설정되었고 점 A를 비롯해
빨간색으로 표시된 점들이 핵심 샘플이다. 점 B, C는 핵심샘플의 이웃이나 조건 2를 만족하지 못하여 핵심샘플으로
분류되지 못했다. N은 핵심 샘플도 아니고 이웃도 아닌 샘플로, 이상치로 판단한다.
X, y = make_moons(n_samples=500, noise=0.05)
print(X)
print(y)
results:
[[ 1.04915527e+00 1.73065790e-01]
[ 1.34329348e+00 -3.42475542e-01]
[ 5.25211174e-01 7.36456178e-01]
.
.
[ 8.35773510e-01 -5.37441872e-01]
[ 2.07619488e+00 4.74647849e-01]
[-1.62802186e-02 9.54408591e-01]]
[0 1 0 0 1 0 0 1 1 0 0 0 0 1 0 1 0 0 1 1 0 1 0 1 1 1 1 0 0 0 1 0 1 1 0 0 0
0 1 1 1 1 0 1 1 0 0 1 1 0 0 1 0 1 0 0 0 0 1 1 0 1 0 1 0 0 0 1 1 0 1 0 1 1
.
.
1 1 1 1 0 1 0 0 1 1 1 0 1 1 0 1 0 0 0 1 1 0 1 1 1 1 1 0 1 0 0 0 1 0 1 0 1
1 0 1 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1 0] for x_i in X:
plt.scatter(x_i[0], x_i[1])
plt.show()
Moon Set 데이터를 불러온뒤, 이를 DBSCAN으로 클러스터링하겠다.
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
print(dbscan.labels_)
result:
[-1 11 0 34 -1 3 4 1 22 9 -1 -1 20 2 -1 -1 3 4 -1 2 17 -1 -1 -1
5 6 -1 4 -1 3 7 35 8 1 -1 29 9 16 10 11 12 13 35 7 33 3 14 8
.
.
22 -1 21 -1 -1 28 36 -1 22 32 8 7 24 -1 2 36 33 -1 -1 4 -1 29 -1 37
24 15 -1 2 32 3 -1 16 -1 -1 2 8 8 24 0 3 -1 -1 -1 -1]DBSCAN 객체를 생성하여 ε은 0.05로, ε-이웃에 존재해야할 최소 수는 5로 설정하였다.
DBSCAN의 labels_ 속성은 DBSCAN 알고리즘이 샘플을 레이블링한 값이다.
-1은 이상치로 판단된 샘플을 의미한다.
DBSCAN의 핵심 샘플의 인덱스는 core_sample_indices_에, 핵심 샘플은 components_ 변수에 있다.
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)
dbscan2 = DBSCAN(eps=0.05, min_samples=5)
dbscan2.fit(X)
ax1 = plt.subplot(1,2,1)
ax2 = plt.subplot(1,2,2)
ax1.scatter(X.T[0], X.T[1], c=dbscan.labels_, cmap='plasma')
ax1.set_title('eps=0.2, min_samples=5')
ax1.grid(linestyle='--')
ax2.scatter(X.T[0], X.T[1], c=dbscan2.labels_, cmap='plasma')
ax2.set_title('eps=0.05, min_samples=5')
ax2.grid(linestyle='--')
plt.show()ε과 최소샘플 수를 달리 적용한 DBSCAN에 대해서 클러스터링 결과를 살펴보자.

'Machine Learning' 카테고리의 다른 글
| 9-3. 군집(Clustering) - 준지도 학습 (1) | 2021.05.21 |
|---|---|
| 9-2. 군집(Clustering) - K평균 클러스터링(2) (0) | 2021.05.20 |
| 9-1. 군집(Clustering) - K평균 클러스터링(1) (0) | 2021.05.20 |
| 8-2. PCA(Principal Component Analysis) (1) | 2021.05.12 |
| 8-1. 차원 축소(Dimensionality Reduction) (0) | 2021.05.12 |