2021. 5. 29. 19:40ㆍFinancial Analysis
What is web scrapingWeb scraping is the process of using bots to extract content and data from a website.
Unlike screen scraping, which only copies pixels displayed onscreen, web scraping extracts underlying HTML code and, with it, data stored in a database. The scraper can then replicate entire website content elsewhere.
Web scraping is used in a variety of digital businesses that rely on data harvesting. Legitimate use cases include:
출처 : https://www.imperva.com/learn/application-security/web-scraping-attack/
위를 직역하자면 웹 스크레이핑이란, 봇을 이용해서 웹사이트로부터 컨텐츠와 데이터를 추출하는 일련의 과정이다.
https://finance.naver.com/item/sise.nhn?code=139480
네이버 금융
국내 해외 증시 지수, 시장지표, 펀드, 뉴스, 증권사 리서치 등 제공
finance.naver.com
먼저 네이버 금융에 접속하여 이마트의 시세를 조회해보자.
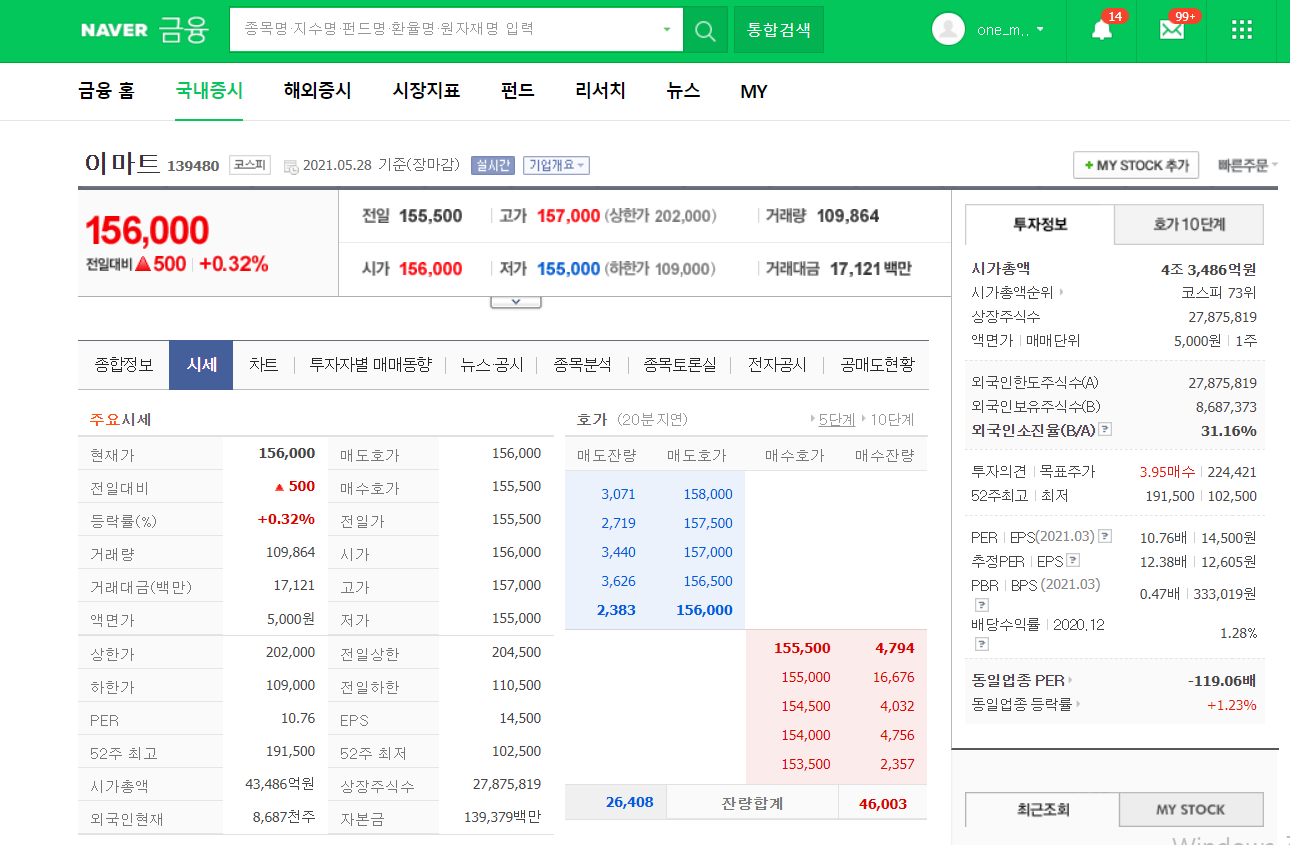
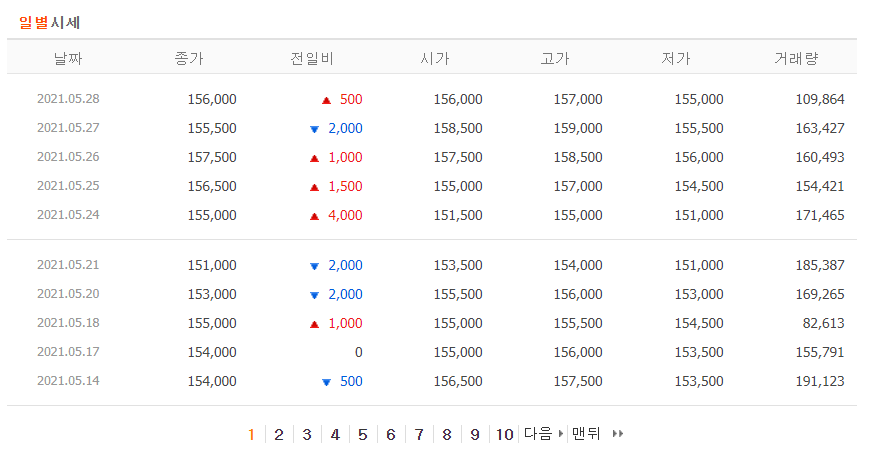
이마트 페이지의 일별 시세를 보면 한 페이지당 주말을 제외한 열흘치의 종가, 시가, 고가, 저가 등의 정보를 담고있다.
이마트가 상장된 이후의 모든 정보를 조회하기 위해서 '맨 뒤' 페이지를 확인한다.
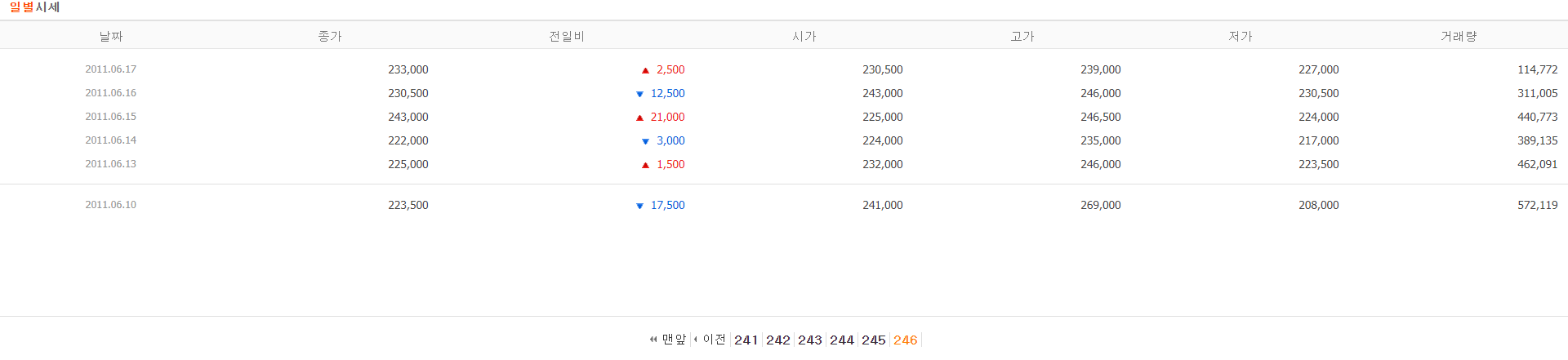
21년 5월 28일 현재 기준으로 총 246페이지가 있으며 2011년 6월 10일부터의 정보를 가지고 있다.

ctrl+U를 통해 페이지 소스코드를 읽으면 html 소스에 'pgRR' 클래스에 해당하는
테이블 데이터에 '맨뒤'라는 글자를 찾을 수 있다. a 태그의 href 속성에 연결되어 있다.
from bs4 import BeautifulSoup
import requests
if __name__ == '__main__':
url = 'https://finance.naver.com/item/sise_day.nhn?code=139480&page=1'
req = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
html = BeautifulSoup(req, 'lxml')
pgrr = html.find('td', class_='pgRR')웹 스크레이핑을 위해서 BeautifulSoup를 import하고, 이마트 일별시세의 첫페이지 url을 requests객체의
get 메소드에 전달한다. 네이버금융이 봇을 차단하는 것을 막기 위해 User-agent에 브라우저 정보도 전달한다.
이 request 객체를 BeautifulSoup에 전달하고, parsing할 방식을 지정한다.
print(pgrr.a['href'])
print(pgrr.prettify())
print(pgrr.text)/item/sise_day.nhn?code=139480&page=246
td class="pgRR">
<a href="/item/sise_day.nhn?code=139480&page=246">
맨뒤
<img alt="" border="0" height="5" src="https://ssl.pstatic.net/static/n/cmn/bu_pgarRR.gif" width="8"/>
</a>
</td>
맨뒤위는 BeautifulSoup 객체의 1) find 함수를 통해 찾은 테이블 데이터의 a 태그의 href 속성과 연결된 링크를 출력하고
2) prettify 함수로 해당 테이블 데이터 객체의 전체 소스를, 3) 마지막으로 text 속성으로 텍스트 정보만 출력한 결과이다.
parsed_url = str(pgrr.a['href']).split('=')
last_page = parsed_url[-1]
print(last_page)
246a 속성의 href와 연결된 위 url에서 맨 끝 246이라는 숫자만을 추출하기 위해
str함수로 '=' string을 기준으로 총 3 토막으로 split한 뒤 배열에 저장하였다.
마지막 인덱스(-1)가 마지막 페이지(246)이다.
이를 이용하여 페이지당 데이터를 데이터 프레임에 담을 것이다.
sise_url = 'https://finance.naver.com/item/sise_day.nhn?code=139480'
total_data = pd.DataFrame()
total_data = read_total_data(sise_url, last_page)시세 정보 url을 지정하고, 전체 페이지의 데이터를 데이터 프레임에 담는다.
전체 페이지의 정보를 읽어오는 함수 read_total_data는 url과 마지막 페이지값을 인자로 받는다.
def read_total_data(url, last_page):
total_data = pd.DataFrame()
for page in range(0, int(last_page) + 1):
data_per_page = read_per_page(url, page)
total_data = total_data.append(data_per_page)
return total_datafor문을 통해 전체 페이지를 순회하여 read_per_page 함수가 반환하는 페이지당 정보를 데이터 프레임에 append한다.
def read_per_page(url, page):
page_url = '{}&page={}'.format(url, page)
req = requests.get(page_url, headers={'User-agent': 'Mozilla/5.0'}).text
page_data = BeautifulSoup(req, 'lxml')
num_extr = page_data.find_all('td', class_='num')
table_header = page_data.find_all('th')
dates = page_data.find_all('span', attrs={'class':'tah p10 gray03'})
columns = list(range(len(table_header)))
index = list(range(len(dates)))
rows = []
rows_buffer = []
for i in range(len(table_header)):
columns[i] = table_header[i].text
for i in range(len(dates)):
index[i] = dates[i].text
for i in range(0,len(num_extr),6):
if num_extr[i].text == '\xa0':
break
for j in range(6):
if j % 6 == 1:
pure_num = num_extr[i+j].text
pure_num = pure_num.replace('\t', '').replace('\n', '')
rows_buffer.append(pure_num)
continue
rows_buffer.append(num_extr[i+j].text)
rows.append(rows_buffer)
rows_buffer = []
data_per_page = pd.DataFrame(rows, columns=columns[1:], index=index)
return data_per_pageread_per_page 함수에서는 해당 페이지의 소스 코드에서 테이블 헤더를 추출하여 text 값을
데이터프레임의 column으로, 날짜 정보의 text 값을 데이터 프레임의 index로 지정한다.
그리고 'num' 클래스에 해당하는 테이블데이터의 텍스트 값을 날짜마다 한 행으로 구성하여
종가, 전일비, 시가, 고가, 저가, 거래량을 데이터프레임에 추가한다.
>>> print(total_data)
종가 전일비 시가 고가 저가 거래량
2021.05.28 156,000 500 156,000 157,000 155,000 109,864
2021.05.27 155,500 2,000 158,500 159,000 155,500 163,427
2021.05.26 157,500 1,000 157,500 158,500 156,000 160,493
2021.05.25 156,500 1,500 155,000 157,000 154,500 154,421
2021.05.24 155,000 4,000 151,500 155,000 151,000 171,465
... ... ... ... ... ... ...
2011.06.16 230,500 12,500 243,000 246,000 230,500 311,005
2011.06.15 243,000 21,000 225,000 246,500 224,000 440,773
2011.06.14 222,000 3,000 224,000 235,000 217,000 389,135
2011.06.13 225,000 1,500 232,000 246,000 223,500 462,091
2011.06.10 223,500 17,500 241,000 269,000 208,000 572,119전체 페이지의 데이터를 스크레이핑하여 출력해보았다.
'Financial Analysis' 카테고리의 다른 글
| 3-2. [트레이딩 전략 구현] 샤프 지수(Sharpe Ratio) (0) | 2021.06.12 |
|---|---|
| 3-1. [트레이딩 전략 구현] 효율적 투자선 구하기 (1) | 2021.06.12 |
| 2-2. DB에서 시세 조회하는 API 만들기 (0) | 2021.06.06 |
| 2-1. 스크래핑한 데이터를 DB에 저장하기 (2) | 2021.06.05 |
| 1-2. 웹 스크레이핑을 통한 일별 시세 분석하기 (2) | 2021.05.29 |