2021. 6. 5. 20:51ㆍFinancial Analysis
주식 데이터를 분석하거나 백테스팅할 경우 일일이 웹에서 스크래핑할 경우 많은 시간을 소요한다.
따라서 먼저 스크래핑하여 한번에 DB에 따로 저장해두고 필요할 때 DB로부터 가져온다면 빠르게 데이터를 처리할 수 있다.
여기서는 MariaDB를 이용한다.
먼저 기업공시채널 홈페이지에 접속하여 KOSPI200 상장 기업의 목록 엑셀 파일을 다운로드 받는다.
https://dev-kind.krx.co.kr/corpgeneral/corpList.do?method=loadInitPage
대한민국 대표 기업공시채널 KIND
업종 전체 농업, 임업 및 어업 광업 제조업 - 식료품 제조업 - 음료 제조업 - 담배 제조업 - 섬유제품 제조업; 의복제외 - 의복, 의복액세서리 및 모피제품 제조업 - 가죽, 가방 및 신발 제조업 - 목
dev-kind.krx.co.kr

다음은 스크래핑 한 결과를 마리아DB에 저장하는 DBUpdater 클래스의 전체적인 구조이다.
import pymysql, json
import pandas as pd
from datetime import datetime
from bs4 import BeautifulSoup
import requests
from Investar import readData
class DBUpdater:
def __init__(self):
"""생성자 : MariaBD 연결 및 종목코드 딕셔너리 생성"""
def __del__(self):
"""소멸자 : MariaDB 연결 해제"""
def read_krx_code(self):
"""KRX로부터 상장법인목록파일을 읽어와서 데이터프레임으로 전환"""
def update_comp_info(self):
"""종목코드를 company_info 테이블에 업데이트한 후 딕셔너리에 저장"""
def read_naver(self, code, company,pages_to_fetch):
"""네이버 금융에서 주식 시세를 읽어서 데이터프레임으로 전환"""
def replace_into_db(self, df, num, code, company):
"""네이버 금융에서 읽어온 주식 시세를 DB에 REPLACE"""
def update_daily_price(self, pages_to_fetch):
"""KRX 상장법인의 주식 시세를 네이버로부터 읽어서 DB에 업데이트"""
def execute_daily(self):
"""실행 즉시 및 매일 오후 다섯시에 daily_price 테이블 업데이트 """하나하나 차근차근 살펴보자.
def __init__(self):
"""생성자 : MariaBD 연결 및 종목코드 딕셔너리 생성"""
self.conn = pymysql.connect(host='localhost', user='root', password='****',
db='Investar', charset='utf8')
with self.conn.cursor() as curs:
sql = """
CREATE TABLE IF NOT EXISTS company_info (
code VARCHAR(20),
company VARCHAR(40),
last_update DATE,
PRIMARY KEY (code))
"""
curs.execute(sql)
sql = """
CREATE TABLE IF NOT EXISTS daily_price(
code VARCHAR(20),
date DATE,
open BIGINT(20),
high BIGINT(20),
low BIGINT(20),
close BIGINT(20),
diff BIGINT(20),
volume BIGINT(20),
PRIMARY KEY (code, date))
"""
curs.execute(sql)
self.conn.commit()
self.codes = dict()
self.update_comp_info()
마리아DB 객체를 처음 생성하면 호출되는 생성자이다.
Pymysql을 이용하면 파이썬 코드 내에서 connection 객체를 통해 DB에 접근이 가능하다.
Investar DB에 접근하여 cursor 객체를 통해 [주식 코드, 회사명, 마지막 업데이트일자]를 저장하는 company_info
테이블과, 일별로 [주식 코드, 일자, 시가, 고가, 저가, 종가, 전일비, 거래량]을 저장하는 daily_price 테이블을 생성한다.
company_info 테이블에서는 주식 코드를 KEY 값으로, daily_price 테이블에서는 주식코드와 일자를 KEY로 설정했다.
sql문은 commit해야 DB에 올바르게 저장된다.

Investar 데이터베이스에 company_info와 daily_price 테이블이 생성된 것을 확인할 수 있다.
DBUpdater 객체에서는 주식 코드와 회사명을 갖는 codes 딕셔너리를 멤버로 가지고 있다.
그리고 update_comp_info 함수를 실행하여 DB의 company_info 테이블을 업데이트하고, 딕셔너리에 저장한다.
def __del__(self):
"""소멸자 : MariaDB 연결 해제"""
self.conn.close()객체가 소멸될 때 소멸자를 호출하여 DB와의 연결을 끊는다.
def read_krx_code(self):
"""KRX로부터 상장법인목록파일을 읽어와서 데이터프레임으로 전환"""
krx = pd.read_html("C:/Users/----/OneDrive/바탕 화면/FinanceAnalysisProject/상장법인목록.xls")[0]
krx = krx[['종목코드', '회사명']]
krx = krx.rename(columns={'종목코드':'code', '회사명':'company'})
krx.code = krx.code.map('{:06d}'.format)
return krxread_krx_code 함수에서는 KOSPI200 상장법인 목록을 읽어온 뒤, '종목코드'와 '회사명' 칼럼만 추출하여 반환한다.
def update_comp_info(self):
"""종목코드를 company_info 테이블에 업데이트한 후 딕셔너리에 저장"""
sql = "SELECT * FROM company_info"
df = pd.read_sql(sql, self.conn)
for idx in range(len(df)):
self.codes[df['code'].values[idx]] = df['company'].values[idx]
with self.conn.cursor() as curs:
sql = "SELECT max(last_update) FROM company_info"
curs.execute(sql)
rs = curs.fetchone()
today = datetime.today().strftime('%Y-%m-%d')
if rs[0] == None or rs[0].strftime('%Y-%m-%d') < today:
krx = self.read_krx_code()
for idx in range(len(krx)):
code = krx.code.values[idx]
company = krx.company.values[idx]
sql = f"REPLACE INTO company_info (code, company, last"\
f"_update) VALUES ('{code}', '{company}', '{today}')"
curs.execute(sql)
self.codes[code] = company
tmnow = datetime.now().strftime('%Y-%m-%d %H:%M')
print(f"[{tmnow}] #{idx+1:04d} REPLACE INTO company_info "\
f"VALUES ({code}, {company}, {today})")
self.conn.commit()
print('')update_comp_info 함수에서는 마지막 업데이트 일자가 없거나 오늘보다 전날이라면, KOSPI200 상장법인의 종목코드와
회사명을 가져와서 codes 딕셔너리에 저장하고 DB의 company_info에 저장한다.
def read_naver(self, code, company,pages_to_fetch):
"""네이버 금융에서 주식 시세를 읽어서 데이터프레임으로 전환"""
try:
url = f'https://finance.naver.com/item/sise_day.nhn?code={code}&page=1'
req = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
html = BeautifulSoup(req, 'lxml')
pgrr = html.find('td', class_='pgRR')
parsed_url = str(pgrr.a['href']).split('=')
last_page = parsed_url[-1]
total_data = pd.DataFrame()
sise_url = f'https://finance.naver.com/item/sise_day.nhn?code={code}'
total_data = readData.read_total_data(sise_url, last_page, pages_to_fetch)
total_data = total_data[::-1]
total_data = total_data.rename(columns={'시가':'Open','고가':'High','저가':'Low','종가':'Close','거래량':'Volume','전일비':'Diff'})
total_data.index = pd.to_datetime(total_data.index)
total_data = total_data.dropna()
total_data["Date"] = total_data.index
total_data = total_data.reset_index(drop=True)
total_data[['Close', 'Diff', 'Open', 'High', 'Low', 'Volume']] = total_data[['Close', 'Diff', 'Open', 'High', 'Low', 'Volume']].astype(int)
total_data = total_data[['Date','Close', 'Diff', 'Open', 'High', 'Low', 'Volume']]
except Exception as e:
print('Exception occured : ', str(e))
return None
return total_dataread_naver 함수에서는 파라미터로 받은 코드에 해당하는 시세 조회 페이지에 접속하여 주어진 페이지 수만큼
스크래핑 해온다. 데이터 프레임을 분석하기 알맞게 가공해준뒤 반환한다.
def update_daily_price(self, pages_to_fetch):
"""KRX 상장법인의 주식 시세를 네이버로부터 읽어서 DB에 업데이트"""
for idx, code in enumerate(self.codes):
df = self.read_naver(code, self.codes[code],pages_to_fetch)
if df is None:
continue
self.replace_into_db(df, idx, code, self.codes[code]) def replace_into_db(self, df, num, code, company):
"""네이버 금융에서 읽어온 주식 시세를 DB에 REPLACE"""
with self.conn.cursor() as curs:
for r in df.itertuples():
sql = f"REPLACE INTO daily_price VALUES ('{code}', "\
f"'{r.Date}', {r.Open}, {r.High}, {r.Low}, {r.Close}, "\
f"{r.Diff}, {r.Volume})"
curs.execute(sql)
self.conn.commit()
print('[{}] #{:04d} {} ({}) : {} rows > REPLACE INTO daily_' \
'price [OK]'.format(datetime.now().strftime('%Y-%m-%d %H:%M'), num + 1, company, code, len(df)))update_daily_price 함수에서는 codes 딕셔너리에 있는 전체 종목의 주식정보를 순회하여
read_naver 함수로 읽어온 데이터프레임을 replace_into_db 함수로 DB에 REPLACE하여 저장한다.
def execute_daily(self):
"""실행 즉시 및 매일 오후 다섯시에 daily_price 테이블 업데이트 """
self.update_comp_info()
try:
with open('config.json', 'r') as in_file:
config = json.load(in_file)
pages_to_fetch = config['pages_to_fetch']
except FileNotFoundError:
with open('config.json', 'w') as out_file:
pages_to_fetch = 100
config = {"pages_to_fetch": 1}
json.dump(config, out_file)
self.update_daily_price(pages_to_fetch)execute_daily 함수는 update_comp_info를 호출하여 상장법인목록을 다시 가져와서 업데이트하고,
json 파일을 읽기모드로 열어서 파일에 적인 pages_to_fetch만큼의 페이지 수 일별시세를 DB에 저장하게한다.
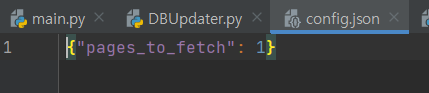
json 파일이 존재하지 않을 경우 쓰기 모드로 파일을 만들어서 100페이지를 읽어오게끔 한다.
이후 실행될 경우를 고려하여 pages_to_fetch를 1로 설정해준다.
책에서는 매일 오후 5시마다 자동으로 execute_daily 함수가 실행되게끔 만들었지만, 형편상 간략하게 구현하였다.

'Financial Analysis' 카테고리의 다른 글
| 3-2. [트레이딩 전략 구현] 샤프 지수(Sharpe Ratio) (0) | 2021.06.12 |
|---|---|
| 3-1. [트레이딩 전략 구현] 효율적 투자선 구하기 (1) | 2021.06.12 |
| 2-2. DB에서 시세 조회하는 API 만들기 (0) | 2021.06.06 |
| 1-2. 웹 스크레이핑을 통한 일별 시세 분석하기 (2) | 2021.05.29 |
| 1-1. 웹 스크레이핑을 통한 일별 시세 읽어오기 (0) | 2021.05.29 |