2023. 2. 12. 21:28ㆍNatural Language Processing
저번 장에서는 말뭉치의 단어들 하나하나에게 인덱스를 부여하는 법을 배웠다.
컴퓨터를 이 단어-인덱스 쌍을 통해서 단어를 인덱스로 이해할 수 있다.
단어를 벡터화해보자.
단어를 벡터화하면 단어 하나에 컴퓨터가 이해할 수 있도록 의미를 담아낼 수 있다.
컴퓨터는 이 벡터를 통해 단어의 의미를 유추해내고, 단어 간의 관계를 계산해낼 수 있다.
단어를 벡터화하는 기본적인 방법 중 하나는 동시발생행렬을 만드는 것이다.
동시발생행렬은 단어 주변에서 같이 존재하는 단어를 통계화한 결과를 행렬로 나타낸 것이다.
다음의 예를 살펴보자.
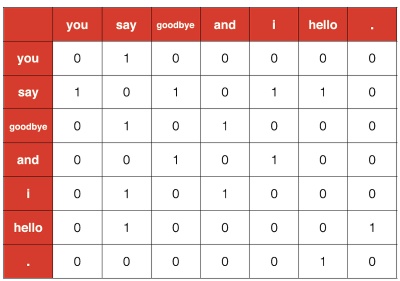
You say goodbye and i say hello.
window를 1로 설정했을 때, you의 경우,
You say goodbye and i say hello.
say만 동시에 나타난다. say에 해당하는 인덱스를 1로 표시하고, 이를 you의 벡터로 만든다.
and의 경우
You say goodbye and i say hello.
goodbye 와 i가 동시에 나타난다. 이 단어들의 인덱스를 1로 설정한다.
각 단어들을 모두 위 방식대로 벡터화하면 아래 그림과 같다.
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
print(C)비틀즈의 let it be 가사 중 일부를 가져와서 이를 동시발생행렬로 만들어주었다.
[[0 1 0 ... 0 0 0]
[1 0 1 ... 0 0 0]
[0 1 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]각 행은 각 단어의 벡터를 나타낸다.
단어를 벡터화한 이유는 단어에 의미를 담아내기 위함이다.
단어 간의 유사도를 측정하는 방법 중 하나는 코사인 유사도를 이용하는 것이다.

코사인 유사도는 위 공식을 사용하여 벡터 간 내적한 결과를 계산한다.
c0 = C[word_to_id['i']]
c1 = C[word_to_id['and']]
print(cos_similarity(c0, c1))
결과:
0.6123724301339324동시발생행렬에서 i의 행과 you의 행의 코사인 유사도를 측정한 결과 0.61을 계산하였다.
most_similar('let', word_to_id, id_to_word, C)
결과:
[query] let
be: 0.49999999823223296
wisdom: 0.4999999979376052
tomorrow: 0.49999999558058256
when: 0.0
is: 0.0most_similiar 함수는 특정 단어를 제공하면 단위발생행렬에서 각 단어마다의 코사인 유사도를 측정하여
가장 유사도가 높은 단어들을 출력한다. let과 가장 유사도가 높은 단어들은 bw, wisdom, tomorrow, when, is이다.
'Natural Language Processing' 카테고리의 다른 글
| [NLP] RNN(순환 신경망) (0) | 2023.02.22 |
|---|---|
| [NLP] word2vec 개선 - 임베딩, 네거티브 샘플링 (2) | 2023.02.19 |
| [NLP] word2vec (0) | 2023.02.13 |
| [NLP] ppmi과 SVD 차원축소 (2) | 2023.02.12 |
| [NLP] 말뭉치 전처리 (0) | 2023.02.12 |