2023. 2. 12. 21:44ㆍNatural Language Processing
단어발생행렬과 코사인 유사도를 통해 측정한 유사도는 한가지 문제점이 있다.
영어의 경우 a나 the 같은 정관사들은 출현빈도가 매우 높은데,
다른 단어들과의 동시발생확률이 높기때문에 코사인 유사도가 높게 측정될 수 있다.
이러한 이유로 만들어진 것이 PMI(pointwise mutual information)이다.

PMI는 전체 corpus에서 단어의 출현빈도가 고려된 유사도 측정 기법이다.
동시발생확률(P(w1, w2))에서 각 w1, w2의 전체 출현빈도가 나누어지기 때문에 단순히 출현빈도가 높은 이유만으로
유사도가 높게 특정되는 일은 없게 된다.
다만 PMI는 log값을 취하기 때문에 동시발생이 일어나지 않았으면(분자가 0) log가 - 무한대이기 때문에
음수는 0으로 처리한 방식이 PPMI이다.
W = ppmi(C)
print(W)
결과:
[[0. 5.183222 0. ... 0. 0. 0. ]
[5.183222 0. 5.768184 ... 0. 0. 0. ]
[0. 5.768184 0. ... 0. 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]]기존 동시발생행렬이 PPMI를 거쳐 변환된 행렬이다.
PPMI 역시 문제가 있는데 이는 희소행렬이라는 점이다.
희소행렬은 특정 위치들을 제외하고는 대부분 0을 값으로 가진 행렬을 말한다.
희소행렬일 경우에 어휘 사전의 크기가 매우 클 경우 차원의 저주에 빠질 가능성이 있다.
이를 위해서 차원 축소를 할 수 있다.
특이값 분해(SVD)는 대표적인 차원 축소 방법인데 행렬에서 중요한 차원만 뽑아내어 행렬의 크기를 감소시킬 수 있다.
U, S, V = np.linalg.svd(W)
print(U[:, :2])
결과:
[[ 1.72929704e-01 2.11431116e-01]
[ 1.40233383e-01 -1.96865320e-01]
[ 1.34319469e-01 1.85117483e-01]
[ 1.89498574e-01 -2.34345853e-01]
.
.
.
[ 8.48612711e-02 -1.07393414e-01]
[ 1.73474774e-01 3.80239896e-02]
[ 1.20473333e-01 -4.91582155e-02]]차원 축소된 U 행렬에서 가장 앞선 2 원소만 추출하였다.
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id,0], U[word_id, 1]))
plt.scatter(U[:,0], U[:,1], alpha=0.5)
plt.show()각 단어마다의 (차원축소된) 단어 행렬을 scatter 그래프로 나타내었다.
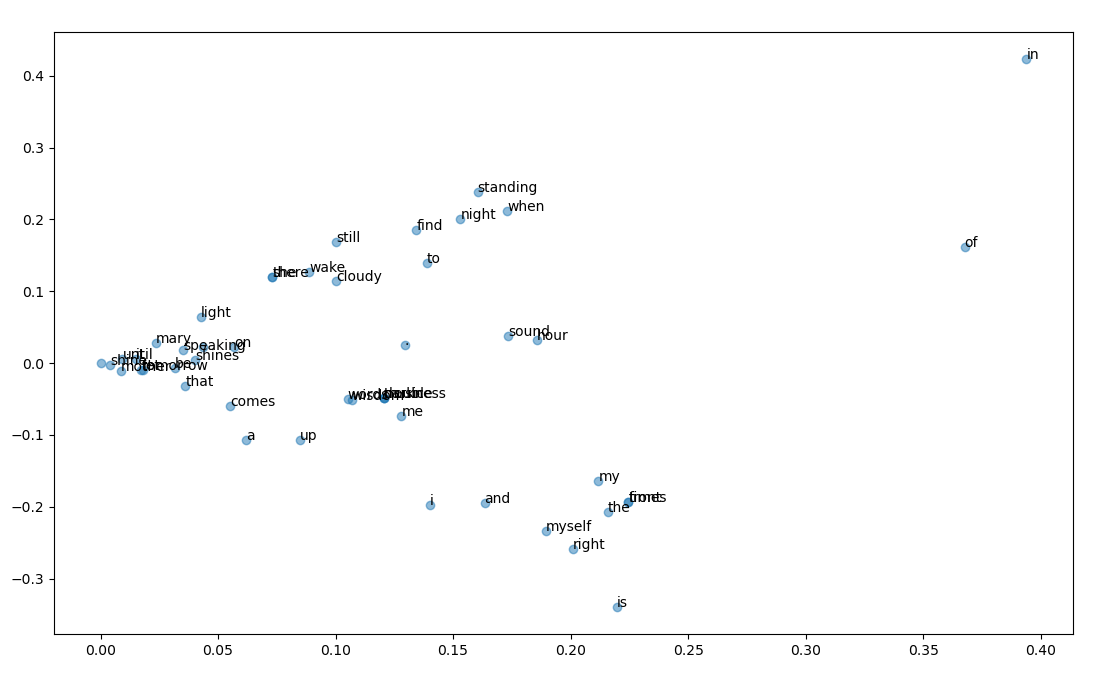
i, my, myself 와 같은 유사 단어들이 밀집된 것을 확인할 수 있다.
'Natural Language Processing' 카테고리의 다른 글
| [NLP] RNN(순환 신경망) (0) | 2023.02.22 |
|---|---|
| [NLP] word2vec 개선 - 임베딩, 네거티브 샘플링 (2) | 2023.02.19 |
| [NLP] word2vec (0) | 2023.02.13 |
| [NLP] 동시발생행렬 (0) | 2023.02.12 |
| [NLP] 말뭉치 전처리 (0) | 2023.02.12 |