2023. 2. 13. 00:16ㆍNatural Language Processing
이전 장에서는 통계 기반의 방식으로 단어를 벡터화하였다.
전체 말뭉치에서 단어가 나타나는 맥락을 읽어들여서 통계화한 뒤, 이 정보를 벡터화하였다.
이번에 알아볼 기법은 추론 기반의 방식이다.
대표적인 추론 기반 기법으로 word2vec 방식이 있다.
word2vec은 신경망을 이용하여 단어를 벡터화한다.
신경망을 훈련시키는 과정을 다시 생각해보자.
신경망에는 입력이 주어지고, 신경망을 통과시켜 어떤 출력을 만들었을 때, 타깃과의 비교를 통해 손실을 계산한다.
word2vec에서는 입력이 맥락이고, 타깃이 중앙 단어이다.
When I find myself in times of trouble.
여기서는 맥락을 다음과 같이 만들 수 있다. (윈도우가 1일 경우)
When I find myself in times of trouble.
I를 예측해야하는 타깃으로, When과 find가 예측의 단서인 입력으로 주어진다.
다른 경우의 입력도 만들 수 있다.
When I find myself in times of trouble.
When I find myself in times of trouble.
신경망은 이러한 입력들을 가지고 추론하고, 타깃과 비교하여 가중치를 갱신한다.
우리는 이전 장에서 살펴보았다시피, 단어들을 컴퓨터가 이해할 수 있는 형태로 입력해주어야한다.
따라서 신경망에 입력되는 데이터는 원 핫 벡터 된 단어이다.
원 핫 벡터를 만드는 방법은 단어 사전의 크기만큼의 벡터에서 단어 인덱스의 원소를 1로 나타내어주면 된다.
ex) find 의 단어 사전 index 가 4이고, 단어 사전의 크기(vocab_size)가 7일 때,
4로 인덱싱된 find의 원핫 벡터 표현은 [0 0 0 0 1 0 0] 이다.
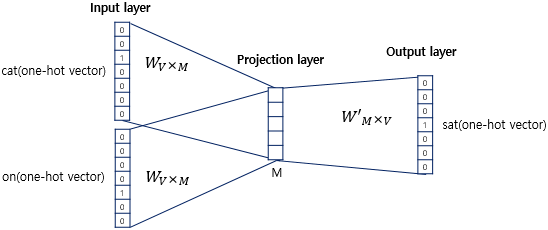
입력층에 원 핫 벡터 표현의 앞 뒤 맥락 단어들을 넣어주고, 은닉층을 거쳐 최종 출력을 계산한다.
입력층에 들어가는 단어 수는 윈도우 크기 * 2인데, 앞 뒤 맥락 모두를 고려해야하기 때문이다.
입력층의 가중치가 곧 각 단어들의 분산 표현이다.
입력층에 들어가는 단어 수가 여러개여도 같은 가중치를 공유하는데, 어차피 원핫벡터 표현에서는
입력층 가중치의 특정 행만 계산되므로(원핫표현과의 행렬곱이라) 이렇게 해도 이상할 것이 전혀 없다.
역전파 때도 같은 값이 흘러들어오기 때문에 가중치 갱신도 동일하게 진행된다.
출력층에서는 단어 사전의 크기(vocab_size)만큼의 값을 출력하는데, 각 단어들의 확률로 해석할 수 있다.
word2vec의 신경망인 CBOW를 구현해보자.
import sys
sys.path.append('..')
import numpy as np
from common.layers import MatMul, SoftmaxWithLoss
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
self.loss_layer = SoftmaxWithLoss()
layers = [self.in_layer1, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
self.word_vecs = W_in신경망에 입력되는 단어의 원핫벡터는 (1, vocab_size) 형상을 띄고 있으므로
W_in 은 (vocab_size, hidden_size)의 형상을, W_out은 (hidden_size, vocab_size)의 형상을 가진다.
마지막 출력층은 소프트맥스를 거친 결과가 (타깃과 비교한) 크로스엔트로피 손실로 계산되었을 때의
손실(Loss)를 출력한다.
그리고 우리가 최종적으로 구하고자 하는 것은 단어의 분산 표현이므로, 입력층의 가중치(W_in)을 따로 저장한다.
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0]) #전체 배치에서, 앞 단어만
h1 = self.in_layer1.forward(contexts[:, 1]) #전체 배치에서, 뒤 단어만
h = (h0 + h1)*0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss순전파(forward) 구현은 위와 같다. 배치 처리를 위해서 전체 배치에서 앞 단어/뒤 단어를 각각 입력층에 통과시키고
이 통과된 값들의 평균을 계산하여 은닉층을 통과시킨다. 마지막으로 출력층에서 score를 계산하고
크로스 엔트로피 손실을 계산하고 손실값을 반환한다.
def backward(self, dout = 1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer0.backward(da)
self.in_layer1.backward(da)
return None역전파는 신경망의 출력층부터 거꾸로 기울기(gradient)를 역전파한다. 역전파 과정에서
가중치가 갱신(update)된다.
이제 CBOW를 구현하였으므로 모델을 훈련시키고 결과를 확인해보자.
import sys
sys.path.append('..')
from common.util import preprocess, create_contexts_target, convert_one_hot
from SimpleCBOW import SimpleCBOW
from common.optimizer import Adam
from common.trainer import Trainer
if __name__ == '__main__':
text = 'When I find myself in times of trouble. Mother Mary comes to me. Speaking words of wisdom, let it be. And in my hour of darkness.She is standing right in front of me.Speaking words of wisdom, let it be. And when the night is cloudy. There is still a light that shines on me. Shine until tomorrow, let it be. I wake up to the sound of music. Mother Mary comes to me. Speaking words of wisdom, let it be.'
corpus, word_to_id, id_to_word = preprocess(text)마찬가지고 비틀즈 - let it be의 가사를 데이터셋으로 모델을 만들어간다.
window_size = 1
hidden_size = 5
batch_size = 2
max_epoch = 1000앞 뒤 하나의 단어들만 고려하고, 은닉층의 크기는 5, 배치 크기는 2, 전체 에포크는 1000회 수행한다.
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
for context in contexts:
print(id_to_word[context[0]], id_to_word[context[1]])전체 텍스트 데이터를 입력과 타깃으로 쓰일 수 있도록 처리해준다.
when find
i myself
find in
myself times
in of
times trouble
.
.문장에서, 입력으로 사용될 contexts는 위와 같이 추출된다.
위 단어 쌍이 주어지면, 모델은 저 가운데에 들어갈 단어(target)를 예측해야한다.
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)그리고나서 입려과 타깃이 신경망에 들어갈 수 있도록 원핫 벡터로 바꾸어준다.
model = SimpleCBOW(vocab_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()optimizer는 Adam으로 설정하고 모델에 입력 데이터를 줘서 훈련시킨다.
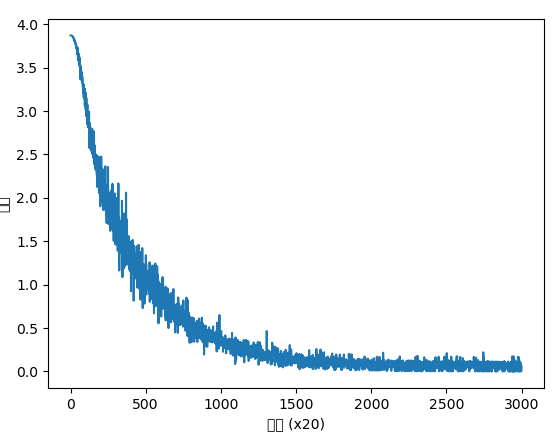
훈련 과정이 진행될 수록 loss가 감소하는 것을 확인할 수 있다.
최종적으로 훈련된 모델의 가중치를 이용하여 예측을 수행해보자.
pred = model.predict([contexts[1][0], contexts[9][0]]).argmax()
# contexts[1][0] : i (의 원핫표현)
# contexts[9][0] : mother (의 원핫표현)
print(id_to_word[pred])
결과:
is
I 와 mother 사이에 들어갈 단어를 예측해보았다.
결과는 'is'으로, 문장을 만들면 I is mother로, 문법에 어긋나지만 문장 자체는 유의미하다.
pred = model.predict([contexts[53][1], contexts[9][1]]).argmax()
# contexts[53][1] : until (의 원핫표현)
# contexts[9][1] : comes (의 원핫표현)
print(id_to_word[pred])
결과:
words두번째로 until _____ comes 의 예측 결과이다.
결과는 until words comes으로, 문법에 살짝 어긋나지만 유의미한 성과를 거두었다.
'Natural Language Processing' 카테고리의 다른 글
| [NLP] RNN(순환 신경망) (0) | 2023.02.22 |
|---|---|
| [NLP] word2vec 개선 - 임베딩, 네거티브 샘플링 (0) | 2023.02.19 |
| [NLP] ppmi과 SVD 차원축소 (0) | 2023.02.12 |
| [NLP] 동시발생행렬 (0) | 2023.02.12 |
| [NLP] 말뭉치 전처리 (0) | 2023.02.12 |